Research

in collaboration with Christoph Goessmann and Elliott Ash
Journal of Law and Empirical Analysis
2026
While recent advances in machine learning and especially text analysis have already transformed empirical legal scholarship, previous work has mostly ignored some of the richest sources of legal data: images and audio. This article contributes to reducing this gap by introducing empirical legal scholars to computer-vision and computational-audio techniques that can be applied to the empirical legal domain. These techniques enable descriptive, causal, and predictive studies that were previously impossible due to scale and computational complexity. After reviewing general approaches to audio and visual machine learning, we illustrate the usefulness of these methods on a sample of videos from the United States Ninth Circuit Court of Appeals.
in collaboration with Mark Verstraete
Iowa Law Review
2025
Financial technology has long relied on data like an applicant's current indebtedness to make decisions about who gets access to new credit, but AI is now enabling credit determinations based on some unusual inputs. This "alternative data"—or data that is not intuitively connected to creditworthiness—includes information like a consumer's online shopping habits, whether they paid their rent and utility bills, and even how many friends they have on social media. The use of this kind of data has exciting potential to expand access to credit but exemplifies a well-known feature of machine learning: It works by finding nonintuitive relationships in large datasets.
Regulators and industry have recognized both the potentials and pitfalls of alternative data. As nascent discussions emerge around appropriate uses of this alternative data, there is little consensus about the ideal shape of regulations for alternative data. This Article offers a path forward for alternative data regulation. In doing so, it surfaces a central tension that regulators must resolve—the contradiction between the desire for intuitive stories and the reality of how these technologies work. For instance, scrolling quickly through an online contract could be indicative of carelessness about legal obligations, which may make someone a risky creditor. Intuitive stories have long formed the basis for social oversight of credit lending. These stories have enabled us to determine that information such as zip codes and medical debt are unfair to include in credit calculations, but that using on-time payment history is acceptable.
Yet the emergence of machine learning models trained on alternative credit data challenges classic assumptions about the connection between data and the narratives we tell. For example, intuition is broken if a person "games" data by changing a proxy for creditworthiness without changing the underlying characteristic a system designer intends to measure. By uncovering this potential for breaking causation, this Article surfaces the true normative stakes of regulating alternative credit data. The stakes are not about "connectedness" between data and decisions, as existing regulations imply.
in collaboration with Erik Stallman
George Washington Journal of Law and Technology
2025
In the 2010s, the open government data movement—a confluence of government transparency and open source advocacy—succeeded in making most federal data disclosed by default and free of restriction on downstream use. However, keen-eyed observers noted a “new ambiguity” in open government data policies. It was not clear if the appropriate focus of these policies was government—in the sense of accountability and transparency—or data—in the sense of downstream use and reuse of government datasets by public and private actors. Even as federal government data policies moved from Executive Branch prerogative to statutory mandate, that ambiguity remained unresolved. But the rise of artificial intelligence—and its accompanying demand for new data sources—tipped the scale in favor of data.
This Article does not seek to resolve the ambiguity in the other direction or rebalance the scales. Instead, this Article articulates how open government principles have a role to play even when federal open data are viewed primarily as an asset or resource to build, train, and test artificial intelligence systems. Further, that role may require refinements in how we think about the “open” part of open government data. There are compelling reasons to condition certain reuses of federal open data on the disclosure of the use even if that would make the use of that data less “open” in some senses.
in collaboration with Elliott Ash, Stefan Bechtold, Mauro Luzzatto
International Conference on AI and Law - 2025
2025
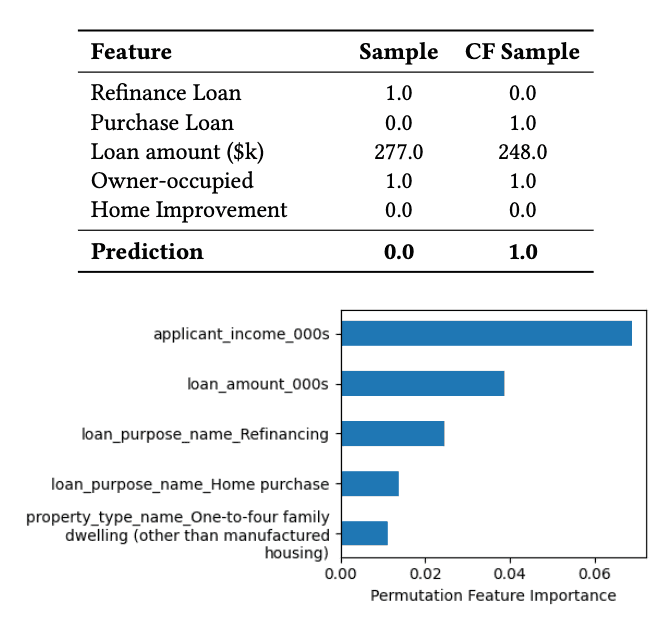
As machine learning and AI models are being integrated into highstakes decisions such as credit lending, parole, and insurance, there is increasing interest in model explainability. A burgeoning literature around eXplainable AI (XAI) has emerged in both law and computer science. This study contributes to this intersection and introduces explainy, a Python library for generating legally relevant machine learning model explanations.
in collaboration with Travis Breaux, Tom Norton, Sarah Santos, Anmol Singhal
International Conference on AI and Law - 2025
2025
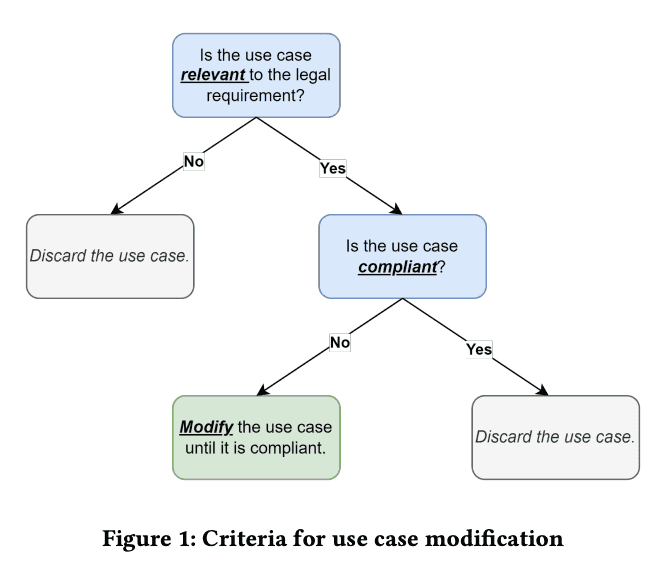
Privacy law and regulation have turned to “consent” as the legitimate basis for collecting and processing individuals’ data. As governments have rushed to enshrine consent requirements in their privacy laws, such as the California Consumer Privacy Act (CCPA), significant challenges remain in understanding how these legal mandates are operationalized in software. The opaque nature of software development processes further complicates this translation. To address this, we explore the use of Large Language Models (LLMs) in requirements engineering to bridge the gap between legal requirements and technical implementation. This study employs a three-step pipeline that involves using an LLM to classify software use cases for compliance, generating LLM modifications for noncompliant cases, and manually validating these changes against legal standards. Our preliminary findings highlight the potential of LLMs in automating compliance tasks, while also revealing limitations in their reasoning capabilities. By benchmarking LLMs against real-world use cases, this research provides insights into leveraging AI-driven solutions to enhance legal compliance of software.
in collaboration with Elliott Ash, Suresh Naidu, Lena Song, Dominik Stammbach
3rd ACM Symposium on Computer Science and Law
2024
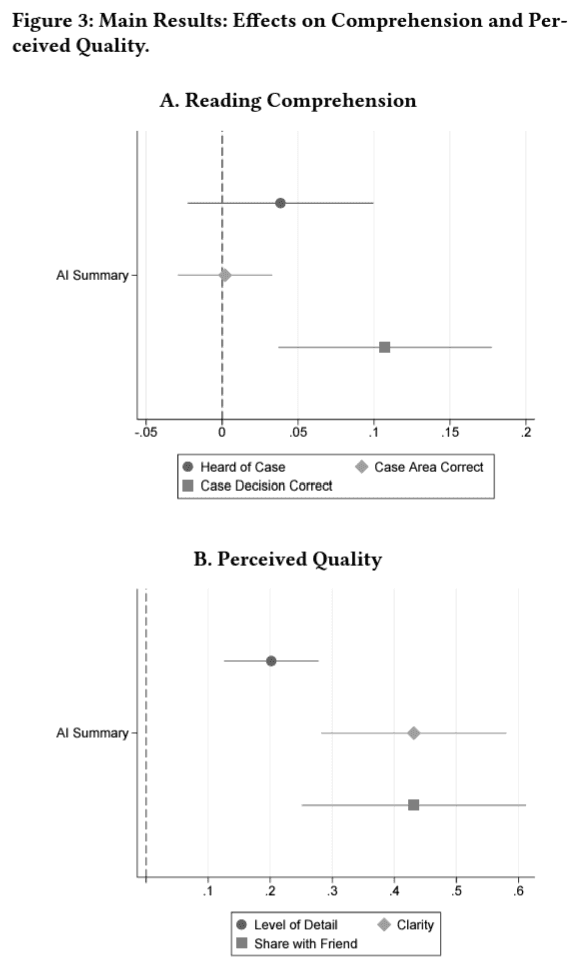
Judicial opinions are written to be persuasive and could build public trust in court decisions, yet they can be difficult for non-experts to understand. We present a pipeline for using an AI assistant to generate simplified summaries of judicial opinions. Compared to existing expert-written summaries, these AI-generated simple summaries are more accessible to the public and more easily understood by non-experts. We show in a survey experiment that the AI summaries help respondents understand the key features of a ruling, and have higher perceived quality, especially for respondents with less formal education.

Over 1.5 million Americans have reported identify theft in recent years, costing the U.S. economy at least $13 billion in 2020. In response to this growing problem, all 50 states have enacted some form of data breach notification law in the past 20 years. Despite their prevalence, evaluating the efficacy of these laws remains elusive. This Article fills this gap, while further creating a new taxonomy to understand these laws.
Legal scholars have generally treated these laws as doing just one thing—disclosing information to consumers. But this approach ignores rich variation: differences in disclosure requirements to regulators and credit monitoring agencies; varied mechanisms for public and private enforcement; and a range of thresholds that define how firms should assess the likelihood that a data breach will ultimately harm consumers.
This Article leverages the Federal Trade Commission’s Consumer Sentinel database to build a comprehensive dataset measuring identity theft rates since 2000. Using staggered synthetic control – a popular method for policy evaluation that has yet to be widely applied in empirical legal studies – this Article finds that whether identify theft laws work depends on which of these different strands of legal provisions are employed. In particular, while baseline disclosure requirements and private rights of action have negligible effects, requiring firms to notify state regulators reduces identity theft rates by approximately 10%. And surprisingly, laws that fail to exclude low-risk breaches from reporting requirements are counterproductive, increasing identify theft rates by 5%. The Article ties together these results within a functional typology: namely, whether legal provisions (1) increase information flows to interested third-parties and regulators, (2) enable mechanisms for public or private enforcement, or (3) balance the costs of consumer confusion with the benefits of disclosure in determining when and how firms must give notice. It explains how these results and typology provide lessons for current federal and state proposals to expand or amend the scope of breach notification laws. A new federal law that simply mimics existing baseline requirements is unlikely to have an additional deterrence effect and may preempt further innovations. At the state level, introducing private rights of action may help at the margins, but likely suffers from well-identified issues of adequately establishing standing and damages. States that close loopholes surrounding breach requirements for encrypted data see lower identity-theft rates, which suggests that other states may be wise to tighten these requirements as well.

in collaboration with Jae Yeon Kim, Sono Shah, Taylor Brown, Tiago Ventura, and Tina Law
PS: Political Science & Politics
2023
Social scientists with data science skills increasingly are assuming positions as computational social scientists in academic and non-academic organizations. However, because computational social science (CSS) is still relatively new to the social sciences, it can feel like a hidden curriculum for many PhD students. To support social science PhD students, this article is an accessible guide to CSS training based on previous literature and our collective working experiences in academic, public-, and private-sector organizations. We contend that students should supplement their traditional social science training in research design and domain expertise with CSS training by focusing on three core areas: (1) learning data science skills, (2) building a portfolio that uses data science to answer social science questions, and (3) connecting with computational social scientists. We conclude with practical recommendations for departments and professional associations to better support PhD students.

in collaboration with Amit Haim
International Conference on Artificial Intelligence and Law - 2023
2023
Is there a limited supply of good image trademarks? Trademark law long rested on the assumption that there is an inexhaustible supply of good marks that provide businesses with sufficient economic advantages to engage in effective branding. However, this conventional wisdom has recently come under scrutiny as evidence has mounted that the number of effective word marks suffers from both depletion of good marks and congestion of similar marks within certain areas. Leveraging new advances in computational social science, we extend this analysis to the study of image marks. We find that there is little evidence for either congestion or depletion in image marks across the most popular areas, but do see some evidence for registered marks being more complex than unregistered marks.

ACM Symposium on Computer Science and Law
2022
Both law and computer science are concerned with developing frameworks for protecting privacy and ensuring fairness. Both fields often consider these two values separately and develop legal doctrines and machine learning metrics in isolation from one another. Yet, privacy and fairness values can conflict, especially when considered alongside the utility of an algorithm. The computer science literature often treats this problem as an ``impossibility theorem" - we can have privacy or fairness but not both. Legal doctrine is similarly constrained by a focus on the inputs to a decision - did the decisionmaker \textit{intend} to use information about protected attributes. Despite these challenges, there is a way forward. The law has integrated economic frameworks to consider tradeoffs in other domains, and a similar approach can clarify policymakers' thinking around balancing utility, privacy, and fairnesss. This piece illustrates this idea by bridging the law and computer science literatures, using a law & economics lens to formalize the notion of a Privacy-Fairness-Utility frontier, and demonstrating this framework on a consumer lending dataset. An open-source Python software library and GUI will be made available to assist regulators and academics in conducting algorithmic audits using this framework.

Illinois Journal of Law, Technology, and Policy
2022
Cybercrime is an increasingly common risk for organizations that collect and maintain vast troves of data. There is extensive literature that explores the causes of cybercrime, but relatively little work that aims to predict future incidents. In 2011, the United States Securities and Exchange Commission (SEC) provided guidelines for how publicly traded companies should convey these risks to potential investors. The SEC and other regulatory agencies are exploring how to leverage artificial intelligence, machine learning, and data science tools to improve their regulatory efforts. This paper explores the potential to use machine learning and natural language processing techniques to analyze firms' mandatory risk disclosure statements, and predict which firms are at the greatest risk of suffering cybersecurity incidents. More broadly, this study highlights the potential for using legally mandated disclosures to bolster regulatory efforts, particularly in the context of prediction policy problems.

Journal of Empirical Legal Studies
2022
As the number of data breaches in the United States grows each year, cybersecurity has become an increasingly important policy area. The primary mechanism for regulating and deterring data breaches is the "data breach notification law." Every U.S. state now has such a law that mandates that certain organizations disclose data breaches to their data subjects. Despite the popularity of these laws, there is relatively little evidence about their effectiveness at deterring breaches, and therefore reducing identity theft. Using medical identity theft panel data collected from the Consumer Financial Protection Bureau (CFPB), this study implements an augmented synthetic control approach to analyze the effect of certain data breach notification standards on medical identity theft.

in collaboration with Jae Yeon Kim
Journal of Online Trust and Safety
2021
Donald Trump linked COVID-19 to Chinese people on March 16, 2020, by calling it the Chinese virus. Using 59,337 US tweets related to COVID-19 and anti-Asian hate, we analyzed how Trump’s anti-Asian speech altered online hate speech content. Trump increased the prevalence of both anti-Asian hate speech and counterhate speech. In addition, there is a linkage between hate speech and misinformation. Both before and after Trump’s tweet, hate speech speakers shared misinformation regarding the role of the Chinese government in the origin and spread of COVID-19. However, this tendency was amplified in the post-Trump tweet period. The literature on misinformation and hate speech has been developed in parallel, yet misinformation and hate speech are often interwoven in practice. This association may exist because biased people justify and defend their hate speech using misinformation.

in collaboration with Joao Caldeira, Alex Fout, and Raesetje Sefala et. al.
Neural Information Processing Systems (NeurIPS) AI For Social Good Workshop
2021
This project presents the results of a partnership between the Data Science for Social Good fellowship, Jakarta Smart City and Pulse Lab Jakarta to create a video analysis pipeline for the purpose of improving traffic safety in Jakarta. The pipeline transforms raw traffic video footage into databases that are ready to be used for traffic analysis. By analyzing these patterns, the city of Jakarta will better understand how human behavior and built infrastructure contribute to traffic challenges and safety risks. The results of this work should also be broadly applicable to smart city initiatives around the globe as they improve urban planning and sustainability through data science approaches.

in collaboration with Sonia Katyal
Berkeley Technology Law Journal
2021
In this Article, we aim to study how well these search engines identify potential conflicts under Section 2(d) of the Trademark Act, 15 U.S.C. §1052(d), which forbids the registration of a trademark that is “confusingly similar” to an existing registered trademark. While a traditional trademark applicant might rely on government-supported techniques (the TESS system) for searching for confusingly similar marks, it turns out that they are often incomplete. Today, because of these various gaps in TESS, several private trademark search engines have emerged to supplement TESS and provide more thorough results. These search engines generally aim to provide a user with a more comprehensive list of potential mark conflicts and recommend whether the user should proceed with their trademark application. Each search engine uses its own methods, algorithms, and techniques to return results. Our study aims to answer the question of which search engines do the best job of returning the most relevant results to a user, and why. We then use our findings to demonstrate how our results potentially affect trademark law by demonstrating the emergence of search costs that are born by the trademark registrant, rather than the consumer.
in collaboration with Chris Hoofnagle and Aaron Perzanowski
George Washington Law Review
2019
Imagine a future in which every purchase decision is as complex as choosing a mobile phone. What will ongoing service cost? Is it compatible with other devices you use? Can you move data and applications across devices? Can you switch providers? These are just some of the questions one must consider when a product is “tethered” or persistently linked to the seller. The Internet of Things, but more broadly, consumer products with embedded software, are already tethered.
While tethered products bring the benefits of connection, they also carry its pathologies. As sellers blend hardware and software—as well as product and service—tethers yoke the consumer to a continuous post-transaction relationship with the seller. The consequences of that dynamic will be felt both at the level of individual consumer harms and on the scale of broader, economywide effects. These consumer and market-level harms, while distinct, reinforce and amplify one another in troubling ways.
Seller contracts have long sought to shape consumers’ legal rights. But in a tethered environment, these rights may become nonexistent as legal processes are replaced with automated technological enforcement. In such an environment, the consumer-seller relationship becomes extractive, more akin to consumers captive in an amusement park than to a competitive marketplace in which many sellers strive to offer the best product for the lowest price.
At the highest level, consumer protection law is concerned with promoting functioning free markets and insulating consumers from harms stemming from information asymmetries. We conclude by exploring legal options to reduce the pathologies of the tethered economy.
in collaboration with Chris Hoofnagle and Damon McCoy
Berkeley Technology Law Review
2018
This Article discusses how governments, intellectual property owners, and technology companies use the law to disrupt access to intermediaries used by financially–motivated cybercriminals. Just like licit businesses, illicit firms rely on intermediaries to advertise, sell and deliver products, collect payments, and maintain a reputation. Recognizing these needs, law enforcers use the courts, administrative procedures, and self–regulatory frameworks to execute a deterrence by denial strategy. Enforcers of the law seize the financial rewards and infrastructures necessary for the operation of illicit firms to deter their presence.
Policing illicit actors through their intermediaries raises due process and fairness concerns because service–providing companies may not be aware of the criminal activity, and because enforcement actions have consequences for consumers and other, licit firms. Yet, achieving direct deterrence by punishment suffers from jurisdictional and resource constraints, leaving enforcers with few other options for remedy. This Article integrates literature from the computer science and legal fields to explain enforcers’ interventions, explore their efficacy, and evaluate the merits and demerits of enforcement efforts focused on the intermediaries used by financially–motivated cybercriminals.